Exploring Link Aggregation Hashing Algorithms in Python
Last week I was stuck in the never ending death scroll on Twitter, and actually came across something pretty interesting. It was a post on Twitter from Christopher Hart deep diving into Equal-Cost Multi-Pathing (ECMP). In this thread he gets into the details of how a switch determines which link in an Ethernet bundle is chosen using hashing algorithms. If you read his thread first, the rest of this post will make more sense.
A common misunderstanding engineers have about Equal-Cost Multi-Pathing (ECMP) and port-channels is that they increase the bandwidth that can be used between two network devices. This *can* be true, but isn't *always* true.
— Christopher Hart (@_ChrisJHart) October 24, 2021
Curious why? 🧵
Now, considering we are dealing with layer-2, let's discuss this in terms of Ethernet frames. When a switch has a frame and needs to pick a link in an ether-channel, it can use information in the layer-2 header (source MAC address and destination MAC address). But what if that frame's payload is something like ICMP, TCP, UDP, OSPF, etc.? Can the switch use additional pieces of information from those higher-layer headers to make a better/different forwarding decision? Hopefully by now its painfully obvious, but the answer is yes, switches and can and do use these higher layers to make forwarding decisions.
Christopher went into incredible detail on how this process works, and quite honestly, it was so well done, there isn't really much to add. But, I did want to look at it from a different angle; that is, from the perspective of how one might implement this behavior in code. So, I wrote a proof-of-concept in Python, and learned a lot along the way.
Defining the Requirements
Before any code is written, we should probably talk about what is needed and how it will integrate into a larger system (say, a switch). First, let's assume our code will have an Ethernet frame in-hand, and a flow tuple with key fields already obtained. Our code will need to calculate something and then deposit the frame into the correct egress queue to be picked up and sent out of the switch via a physical interface. We also will assume there is some other sub-system that handles the physical stuff relating the the interface bundle itself (tracking interface state, re-bundling, mapping queues to physical interfaces, grabbing frames from the queues, and sending the electrical/optical signals on the media). To summarize, our code's "job" is to read the frame and packet headers, determine the correct hashing algorithm, perform the hash, choose an egress queue based on that hash, and deposit the frame into that queue.
Information Gathering
Let's take a deeper look into the frame and packet headers to see what information is there, and which fields we may or may not want to use in order to make forwarding decisions (key fields). In order, we'll look at Ethernet, IP, TCP, UDP, ICMP, and finally OSPF headers.
Ethernet Frame Header
An Ethernet frame has a field called Ethertype which describes what type of payload is contained in the frame. It can contain many different things, but for IP packets, this value will be 0x0800.

IP Packet Header
Now that we know that, let's look into the IP header and see what we have to work with. IP headers have a field called Protocol. This field can contain any one of the registered IANA protocol numbers. For this example implementation we will focus on the most common protocols of TCP (6), UDP (17), and ICMP (1). Just to show something a little different though, we'll throw OSPF (89) in there as well.

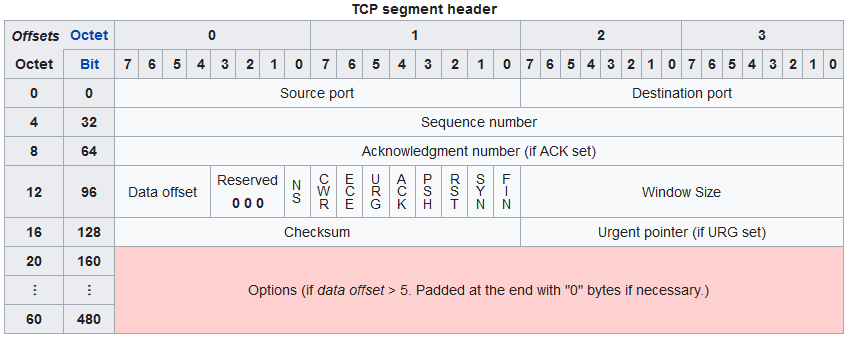
TCP Segment Header
There are really only two pieces of information in this header that we want to make a forwarding decision with, and those are source and destination port number.
UDP Datagram Header
The UDP datagram header is similar to TCP in such that we only need the source and destination ports for use as key fields.

ICMP Packet Header
Inside of the ICMP header there are fields related to type and code. For example, an ICMP request is (8, 0), echo-reply is (0,0), and TTL-exceeded is (11,0). But for our purposes, none of this is really useful to load-balance across links in a bundle, therefore there will be no key fields taken from ICMP packet headers.

OSPF Packet Header
There are five different message formats for OSPF depending on what the protocol is trying to accomplish. Those are Hello, DBD, LSR, LSU, and LSAck. I won't get into the message format minutia, but suffice it to say, those do not contain anything for which we might want to make a forwarding decision. Therefore, there will not be any key fields in the OSPF packet header for this implementation.
Load-Balancing Methods
Now that we have teased out the information needed from each of the protocol headers, we need some logic to determine which method of load-balancing we need to do for each of the respective protocols. And let's not forget a fail-safe. If we cannot read any of the frame/packet information, we still should pick and egress interface and send the frame. We cannot just drop the frame on the floor. The three methods that will be supported are as follows (and a fail-safe):
mac-address- Uses the source and destination MAC address.ip-address- Uses the source and destination IP address.port-proto- For TCP & UDP packets, source IP, source port, destination IP, destination port, and protocol.fail-safe- This is chosen as a last resort, and uses the abovemac-addressmethod.
Hashing Algorithms
For each of the above load balancing methods, we will need to develop a hashing algorithm that will generate a deterministic result. That's just a fancy way of saying, given some inputs like source MAC and destination MAC, the resulting hash will be the same for each pass through the hashing algorithm. This is the where I think the "vendor magic" comes in. This is where one can get creative and load-balance in any number of ways. If vendor A can do this in a more efficient manner than vendor B, then perhaps they can forward more frames per second than their competitor, or maybe vendor A does it in such a way where real traffic patterns are balanced more evenly than with vendor B.
In my first attempt of building an algorithm for the mac-address method, I resorted to taking the four least-significant bits from the source and destination MAC address, concatenating them, and taking that eight-bit representation and converting that back into an integer. The resulting value is some value between 0-255.
def hash_src_dst_mac(frame: Frame):
"""Hash function for source mac address and destination mac address.
Args:
frame (Frame): Network Frame object
Returns:
int: Returns integer between 1 and 256
"""
# convert to binary, strip '0b', and zero-pad
src_mac = bin(int(frame.src_mac, 16))[2:].zfill(16)
dst_mac = bin(int(frame.dst_mac, 16))[2:].zfill(16)
# take the last n (least significant) bits and concatenate
src_bin = bin(int(src_mac))[::2][-4:]
dst_bin = bin(int(dst_mac))[::2][-4:]
hash_bin = src_bin + dst_bin
return int(hash_bin, base=2)
The above method does what we want, but let's consider the efficiency of this code. If we run 1 million frames through it, we get the following results.
❯ python -m linkagg 8 1000000
One frame for every flow only. We should see a uniform distribution
==================================================
Egress Queue 1: 124901 frames
Egress Queue 2: 124741 frames
Egress Queue 3: 125336 frames
Egress Queue 4: 125266 frames
Egress Queue 5: 124928 frames
Egress Queue 6: 124999 frames
Egress Queue 7: 124975 frames
Egress Queue 8: 124854 frames
==================================================
Total hashing time: 5013.136148452759 msClearly that performance sucks! Five seconds to egress 1 million frames. There is no way we could ship something that slow. Now lets see what we can do to improve performance by adjusting the algorithm. Instead of doing this weird string slicing, concatenation, binary conversion, and conversion back to an integer, lets think more low-level. Something that can be implemented in an ASIC or FPGA. For this lets use an XOR operation (which is really just a type of logic gate which an ASIC or FPGA have many of). The below diagram shows what exactly an XOR operation does. Given inputs A and B, some reduced result is produced. The table in the diagram shows all possible combinations and their respective result.
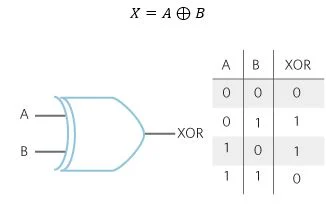
So what does this mean for our hashing algorithm? First, we'll take the two MAC addresses (RED), perform a bitwise XOR operation on them (YELLOW), keep only the eight least significant bits by taking a bitwise AND with 11111111 (255) (ORANGE) (Remember those CCNA studies where you had to subnet by hand? This was bitwise ANDing 🤯). What we are left with is a resulting set of zeros and ones, that we can represent as an integer (142 in this example) (GREEN).

Below is the code using this optimization:
def hash_src_dst_mac(frame: Frame):
"""Hash function for source mac address and destination mac address.
Args:
frame (Frame): Network Frame object
Returns:
int: Returns integer between 1 and 256
"""
# Convert hex str to int, take XOR and keep only the 8-most least significant bits
return (int(frame.src_mac, 16) ^ int(frame.dst_mac, 16)) & 255
Below are the results from the optimized code:
❯ python -m linkagg 8 1000000
One frame for every flow only. We should see a uniform distribution
==================================================
Egress Queue 1: 125044 frames
Egress Queue 2: 124749 frames
Egress Queue 3: 124959 frames
Egress Queue 4: 125256 frames
Egress Queue 5: 124994 frames
Egress Queue 6: 124974 frames
Egress Queue 7: 124839 frames
Egress Queue 8: 125185 frames
==================================================
Total hashing time: 2014.3201351165771 msThis is looking better! We are now just over two seconds to egress 1 million frames. Let's see if we can squeeze out any more optimization by using Cython to compile the hashing functions into a compiled C module. In order to do this, we need to rename our Python (.py) file to (.pyx), modify a few bits in our functions, and use Cython to generate C code and compile it into a C module that we can use in Python, just as if it were native Python code.
Below is an example of the Cython code:
def hash_src_dst_mac(frame: Frame):
"""Hash function for source mac address and destination mac address.
Args:
frame (Frame): Network Frame object
Returns:
int: Returns integer between 1 and 256
"""
cdef long src_mac, dst_mac
cdef int keep
src_mac = int(frame.src_mac, 16)
dst_mac = int(frame.dst_mac, 16)
keep = 255
# Convert hex str to int, take XOR and keep only the 8-most least significant bits
return (src_mac ^ dst_mac) & keep
With that complete and compiled, below are the results of our cythonized module:
❯ python -m linkagg 8 1000000
One frame for every flow only. We should see a uniform distribution
==================================================
Egress Queue 1: 124869 frames
Egress Queue 2: 125184 frames
Egress Queue 3: 125364 frames
Egress Queue 4: 125042 frames
Egress Queue 5: 125131 frames
Egress Queue 6: 124423 frames
Egress Queue 7: 125557 frames
Egress Queue 8: 124430 frames
==================================================
Total hashing time: 1550.9333610534668 msOk, this is looking even better! We've managed to squeak out a little more performance, and are coming in at just over 1.5 seconds. Now, I am a Cython newbie, and I'm sure it might be able to be optimized even more, but this ain't production, and I'm not a real software developer. So we'll leave it be for now.
Egress Queuing
The hard part is done now and its time to deposit the frames into the various egress queues in order to have the egress interfaces send them out on the wire. This is done by taking the number of supported interfaces in a bundle on our switching platform, the number of interfaces that are active in the bundle, and the hash value from all of the previous work. We can then divide the number of queues by the number of active interfaces to get our mapping from hash value to egress queue. See the below diagram which helps to illustrate the point.
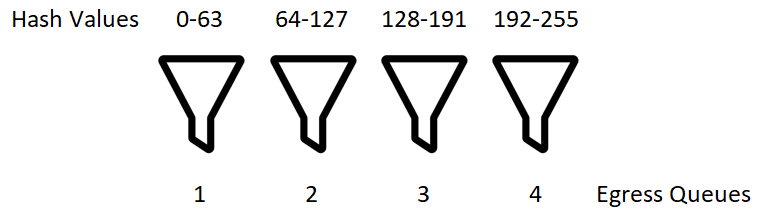
The process of calculating the windows for which to dump into each queue is why the number of active interfaces and number of supported interfaces in a bundle is needed. We have to calculate these widths dynamically. Below is the code that does this mapping.
def egress_intf_picker(number_of_up_intfs, max_supported_intfs, hash_value):
"""Function that uses the resulting frame hash and computes which up
interface queue the frame will be put in. The system as a whole should then
map these queues to actual egress interfaces.
Args:
number_of_up_intfs (int): Number of operational interfaces in the bundle
max_supported_intfs (int): Maximum number of interfaces that can be supported in a bundle
hash_value (int): Resulting frame hash from the hashing process
Raises:
NoAvailableInterfaces: If there are no available interfaces in the bundle, just raise an exception
Returns:
int: Egress queue to dump the frame into. This will be picked up by an egress interface in the bundle
"""
# calculate windows for what hashes go into which egress interface "bucket"
# short-circuit if no interfaces are up
if number_of_up_intfs == 0:
raise NoAvailableInterfaces(
"There are currently no up egress interfaces in the bundle"
)
window_width = max_supported_intfs // number_of_up_intfs
for i in range(number_of_up_intfs):
idx = i + 1
lower = window_width * (idx - 1)
upper = window_width * idx
if lower <= hash_value < upper:
return idx
Testing the Code
I knew from the outset that I would need some testing to validate things as I went along. First, I wanted to make sure the building blocks did what they were supposed to, but also, as I started making code optimizations, tests were critical to ensuring that I didn't break anything along the way. And in fact, there were several times where I made changes and thought they were good to go, but all of a sudden, some or all of the tests were failing. Without testing, I would never have known when and what I broke.
I have never used true test-driven development (TDD) before, but I tried it out during this process and really fell in love with it. For those that are not familiar, strict TDD states that you should write tests first, and ensure that they fail. Once you see that they have failed, write your code until they pass. This also has the side-benefit of allowing me to think about the piece of code under test, and what I need to give as inputs, and what I expect as outputs, without having to think about how I am going to implement it.
For this project I used pytest which is probably the most well-known and widely adopted testing framework for Python. With miniman effort, it allows for robust testing of your Python code. There are plenty more tests I could have written, but for this project I only wrote the following tests:
test_frames- Tests the frame generator that generates sample frames for testing the hashing algorithms.test_one_intf- Tests the system with just one interface/queue.test_link_distribution- Tests the frame distribution to make sure we have well-dispersed load across all of the queues.test_hashses_are_deterministic- Tests that a hashing algorithm, provided the same inputs, will return the same outputs (deterministic).
Below is output from running pytest:
❯ pytest -v
======================= test session starts =======================
platform linux -- Python 3.9.7, pytest-6.2.5, py-1.10.0, pluggy-1.0.0 -- /home/jccurtis/code/personal/linkagg/venv/bin/python
cachedir: .pytest_cache
rootdir: /home/jccurtis/code/personal/linkagg
collected 5 items
tests/test_linkagg.py::test_version PASSED [ 20%]
tests/test_linkagg.py::test_frames PASSED [ 40%]
tests/test_linkagg.py::test_one_intf PASSED [ 60%]
tests/test_linkagg.py::test_link_distribution PASSED [ 80%]
tests/test_linkagg.py::test_hashes_are_deterministic PASSED [100%]
======================== 5 passed in 0.29s ========================Send It!
Ok, that was a lot of work to make it to this point. Now its time for the ultimate test. Let's send some frames through the system and observe the behavior.
In order to really put it through its paces a frame generator was built for the project because I don't have access to a traffic generator. This frame generator generates fake frames with random MAC addresses, random IP addresses, random port numbers, and random protocol numbers (from our list of TCP, UDP, ICMP, and OSPF). This Python Frame object has a method called Frame.flow_tuple() which will give us our key field information in order to run through the hashing algorithm that is most applicable. So if a random frame happens to be ICMP, it would use the ip-address hashing method, or if the frame was TCP, it would use the port-proto method, etc.
So, let's experiment a little...

One Flow with 10000 Frames
❯ python demo_one_flow.py 8 1
Flow Tuple: ('9e227ab82d0b', '686c0d075418', 6, '231.76.209.165', 9879, '238.189.236.253', 35566)
==================================================
Egress Queue 1: 0 frames
Egress Queue 2: 0 frames
Egress Queue 3: 0 frames
Egress Queue 4: 0 frames
Egress Queue 5: 0 frames
Egress Queue 6: 10000 frames
Egress Queue 7: 0 frames
Egress Queue 8: 0 frames
==================================================
Total hashing time: 8.985042572021484 mThe above is a TCP flow, and it looks like our hashing algorithm is working!
8 TCP Sessions, 8-link Bundle Using Mac-Address Hashing
('001122334455', '554433221100', 6, '119.130.98.86', 60587, '211.120.117.96', 36960)
('001122334455', '554433221100', 6, '98.212.153.216', 16367, '189.116.58.30', 31233)
('001122334455', '554433221100', 6, '116.19.188.171', 65071, '183.115.196.221', 1561)
('001122334455', '554433221100', 6, '43.228.46.205', 38229, '230.10.181.129', 64085)
('001122334455', '554433221100', 6, '32.127.177.82', 45710, '139.157.80.210', 5416)
('001122334455', '554433221100', 6, '162.198.209.21', 57670, '217.231.154.151', 39946)
('001122334455', '554433221100', 6, '118.246.173.180', 2804, '248.119.124.199', 1607)
('001122334455', '554433221100', 6, '97.226.58.132', 13831, '36.164.12.243', 204)
==================================================
Egress Queue 1: 0 frames
Egress Queue 2: 0 frames
Egress Queue 3: 8000 frames
Egress Queue 4: 0 frames
Egress Queue 5: 0 frames
Egress Queue 6: 0 frames
Egress Queue 7: 0 frames
Egress Queue 8: 0 frames
==================================================Looks like the MAC address based hashing algorithm is working as intended, but that does not load-balance like we had hoped. The next example will be the same, except this time, we'll choose the port-proto hashing algorithm.
8 TCP Sessions, 8-link Bundle Using Port-Proto Hashing
('001122334455', '554433221100', 6, '247.133.53.184', 6968, '17.96.88.240', 31596)
('001122334455', '554433221100', 6, '123.103.46.4', 22427, '72.35.208.123', 44685)
('001122334455', '554433221100', 6, '82.82.45.247', 55968, '62.227.48.232', 44088)
('001122334455', '554433221100', 6, '28.128.146.125', 44329, '7.46.77.190', 11561)
('001122334455', '554433221100', 6, '71.159.64.97', 54211, '241.35.137.112', 29948)
('001122334455', '554433221100', 6, '24.2.233.62', 8784, '69.247.255.102', 5283)
('001122334455', '554433221100', 6, '8.193.14.64', 64263, '29.110.10.64', 6957)
('001122334455', '554433221100', 6, '55.175.208.99', 53006, '199.160.13.184', 923)
==================================================
Egress Queue 1: 1000 frames
Egress Queue 2: 2000 frames
Egress Queue 3: 1000 frames
Egress Queue 4: 1000 frames
Egress Queue 5: 1000 frames
Egress Queue 6: 1000 frames
Egress Queue 7: 1000 frames
Egress Queue 8: 0 frames
==================================================Now we have a much more uniform distribution, just by choosing a different hashing algorithm.
8000 Random Flows on an 8-link Bundle
❯ python -m linkagg 8 8000
One frame for every flow only. We should see a uniform distribution
==================================================
Egress Queue 1: 1033 frames
Egress Queue 2: 992 frames
Egress Queue 3: 1009 frames
Egress Queue 4: 1044 frames
Egress Queue 5: 997 frames
Egress Queue 6: 958 frames
Egress Queue 7: 989 frames
Egress Queue 8: 978 frames
==================================================
Now lets see it with two elephant flows. Sometimes those will hit the same interface
==================================================
Egress Queue 1: 1033 frames
Egress Queue 2: 10992 frames
Egress Queue 3: 1009 frames
Egress Queue 4: 11044 frames
Egress Queue 5: 997 frames
Egress Queue 6: 958 frames
Egress Queue 7: 989 frames
Egress Queue 8: 978 frames
==================================================
Total hashing time: 27.418851852416992 msAs expected, we see approximately 1,000 frames across each of the 8 queues. But obviously communication over a network between two endpoints is never just one frame, its many frames. So looking at the latter half of the above output,we see two flows that have a lot of data (therefore many frames). This illustrates Christopher's point about load-balancing across an Ethernet bundle does not always mean you can get the full, aggregate bandwidth over a single flow, or across the whole bundle for that matter. Sometimes you might just be really unlucky! Or perhaps you have a couple "elephant" flows that will utilize all of a single link's bandwidth in a bundle. If you do run into the situation where you have poor distribution, changing the hashing algorithm on the bundle may cause the distribution of traffic to be more even. With that said, even if you do manage to get a uniform distribution of frames across the bundle, individual frame sizes can and will differ greatly. They can be from 64 bytes all the way to 1522 bytes (Ethernet and 802.1q headers included), or larger if there are jumbo frames and higher IP MTUs permitted over the network. So, while you might expect to see equal interface utilization because you are seeing equal frame distribution, that may not actually be what you observe (think, large packets with video streaming vs. tiny packets for syslog data).
To give a concrete example, lets say you have a video service running on a server, and you have 8000 concurrent clients watching that video at any given time. Let's also say that the uplinks from that server's switch are bundled and are connected upstream to a layer-3 switch, which then connects to a routed network to where your clients are located. With this setup, there are 8000 TCP sessions established and the high-bandwidth video traffic is leaving from the server to 8000 individual clients. If the Ethernet bundle's hashing algorithm set to mac-address, we would see 100% of the traffic pinned to a single interface. If you recall from CCNA studies, the MAC addresses in an Ethernet frame header are specific to the broadcast domain, and are stripped and re-added as a packet traverses from one interface to another on a layer-3 boundary. Given this information, if we were to adjust our hashing algorithm to ip-address or port-proto, the frames would immediately start being distributed more evenly across the bundle.
Summary
In summary, this was a fun thought exercise and I enjoyed writing it. I appreciate Christopher's Twitter thread that prompted this. It's always good to know how the things we configure in our networks actually work, as it gives us a better understanding of the implications and possible failure scenarios that might arise. Hopefully when you encounter this in your network, you will be better prepared to spot the issue, understand what is happening, and know immediately how to fix it.
Code Repository
The accompanying code for this blog post is located here.
There are three git branches in the repository:
inefficient- Shows the first example of hashing which is pretty slow.efficient- An optimized, pure Python example of hashing which is a bit faster.cythonized- A Cython-optimized hashing module which is the fastest version in this implementation. This branch has been merged into themainbranch.